
Choosing an Optimal Kubernetes Worker Node Size
Specific recommendations for your startup


This post focuses on helping startups choose the optimal number of worker nodes and their sizes to run their applications reliably while minimizing waste of resources. While the question of node-sizing is universal to everyone running applications of Kubernetes, the right answer for each of them is different because of the sheer number of factors that influence it over time.
But when setting up the nodes in your Kubernetes cluster for the first time, how do you make that first educated decision? Which factors are most important to consider when you’re choosing your nodes the first time? And why?
This post shares an understanding of the most important factors to consider for a startup that runs less than 10 microservices and runs a total of 3-4 environments. We will also give specific recommendations that are based on what we’ve seen to have worked well for other startups operating at a similar scale.
Note: This article uses “nodes” and “worker nodes” synonymously. We don’t discuss master node sizing in this post.
What are the Different Node Sizing Strategies?
Given a desired target capacity (i.e. a combination of CPU cores & RAM) of a cluster, you have three node-sizing strategies to choose from
- Many Small Nodes: All small nodes of the same capacity
- Few Large Nodes: All large nodes of the same capacity
- Heterogeneous Nodes: A mix of small and large nodes
For example, let’s say you need a capacity of 16 CPU cores and 64 GB of RAM to run your different applications on your cluster. Below are just 3 possible ways of choosing your node sizes in your cluster:
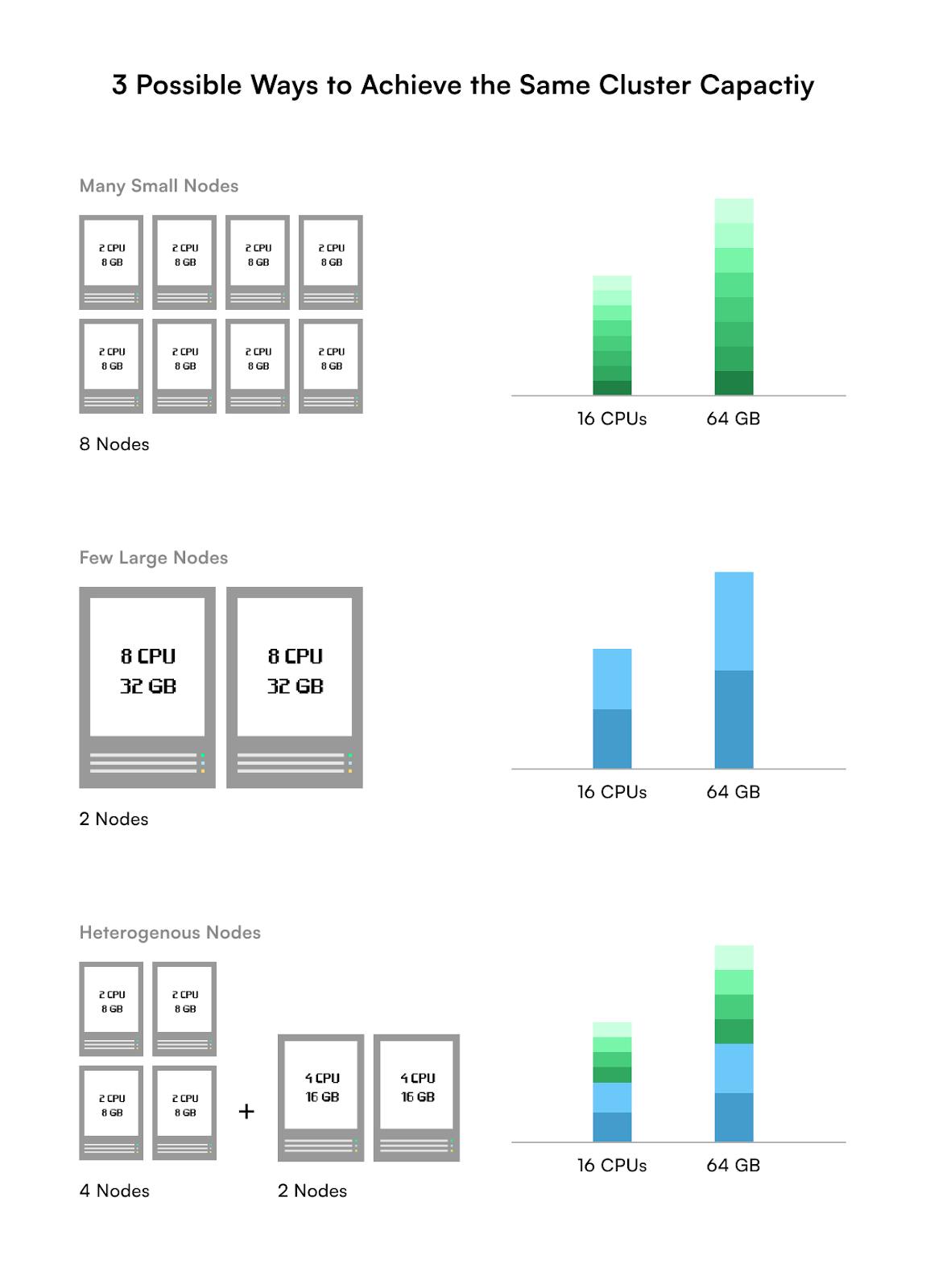
Each of the above options gives you the desired capacity of 16 CPUs and 64 GBs of memory. But which one should you choose?
Many Small Nodes or Few Large Nodes
The size of any node should be at least as much as the maximum of the required capacities of the applications that you want to run on it.
Assuming you want to run applications a1, and a2 on node n.
Capacity(n) >= Max of [max_required_capacity(a1), max_required_capacity(a2) ]
For example, to run a deep learning application that requires 10 GB of memory, you need a node that has at least 10 GB of memory.
Now, assuming you’re ensuring the above, which factors do you consider before choosing node sizes.
Note: The recommendations shared in the below sections are strictly for startups having <10 microservices and a total of 3-4 environments.
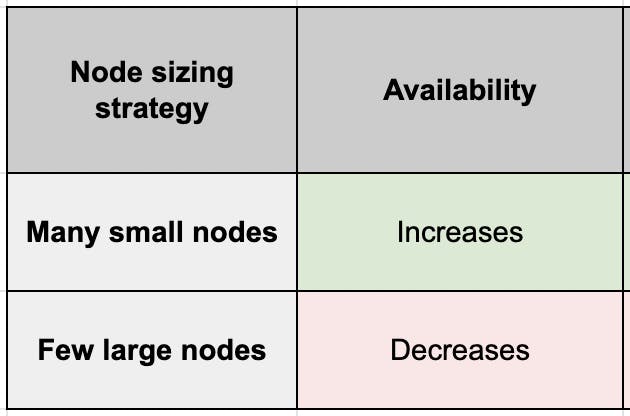
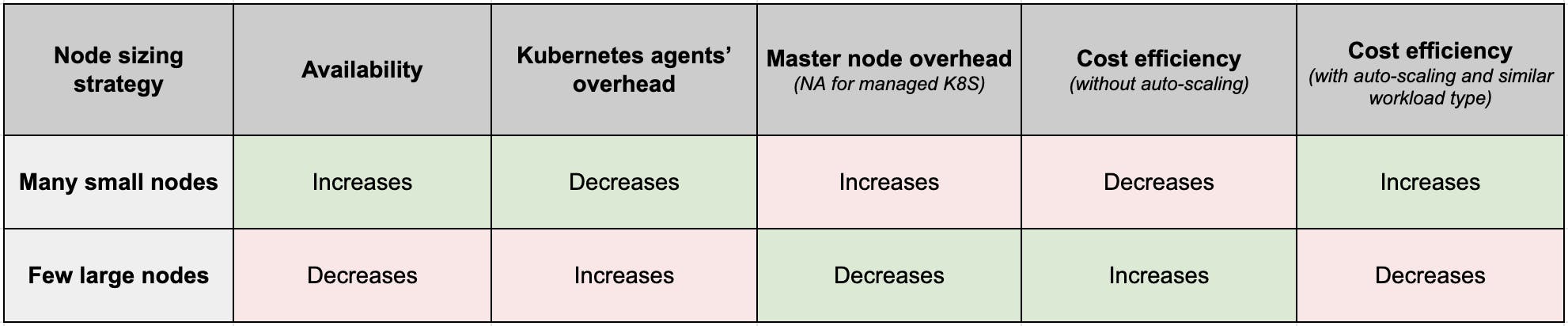
Availability
Within a cluster, the more the nodes, the more the availability.
Why?
Every node that goes down reduces the availability of your application by 1/n. The larger the n (number of nodes), the lesser the impact on your availability.
For example,
If there’s a cluster with 2 large worker nodes and you lose one, you lose 50% of your capacity. Unless you overprovision your node capacity by 100%, your cluster will not be able to handle double the load.
But if your cluster has 5 nodes and you lose 1 of them, you lose just 20% of your cluster capacity. Your remaining live nodes are more likely to be able to distribute and handle this load among themselves. So fewer parts of your application may go down, if at all, as compared to having only 1 node remaining, as in the previous case.
Note: This is also referred to as Replication. The more the replication, the higher the availability.
Let’s plot this on a comparison table that we’ll keep adding more factors as we move forward in the post:
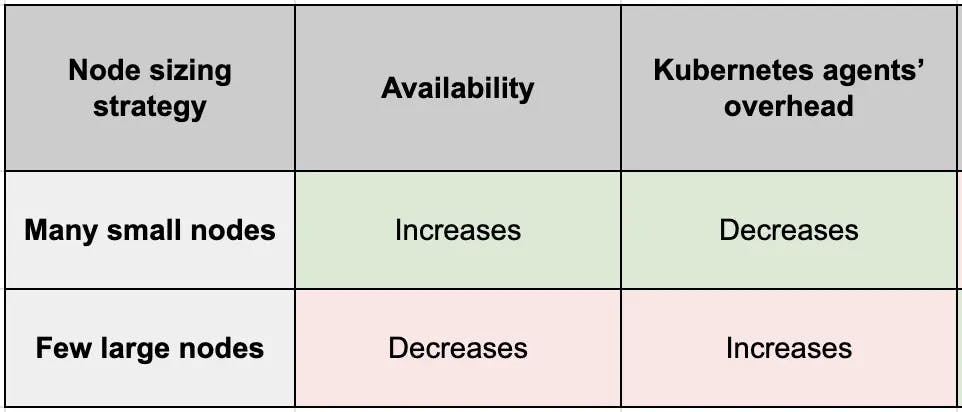
Overhead for Kubernetes Agents
As the number of nodes decreases, each node is required to handle a larger percentage of the same workload, which leads to an increase in the number of pods that run on each node.
So, fewer large nodes lead to many more pods per node which leads to more containers per node.
Now, Kubernetes agents perform various tasks on every node to manage the containers running on that node. For example:
- cAdvisor collects and analyzes the resource usage of all containers on a node
- kubelet runs regular liveness and readiness probes against each container on a node
More containers mean more work for cAdvisor and kubelet in each iteration.
So, the more the pods → The more the overhead on the agents to manage these pods → The slower the system becomes, and can even become unreliable after hitting the pod threshold.
Basically, you don’t want to choke your Kubernetes agents. To simplify this, both Kubernetes and different managed Kubernetes services recommend and/or put a hard limit (threshold) on the number of pods that can be scheduled on a node.
💡 Here’s a quick reference for determining pod limits:
- Kubernetes: Recommends (or can reliably support) No more than 110 pods per nodeNo more than 150000 total pods in a cluster
- Google Kubernetes Engine (GKE): Limits it to 100 pods per node irrespective of the size of the node.
- Azure Kubernetes Service (AKS): Allows up to 250 pods per node irrespective of the size of the node.
- Amazon Elastic Kubernetes Service (EKS): Imposes a pod limit depending on the node size. For example, t3.small allows only 11 pods, while m5.4xlarge allows 234 pods.
Our comparison table now looks like the below:
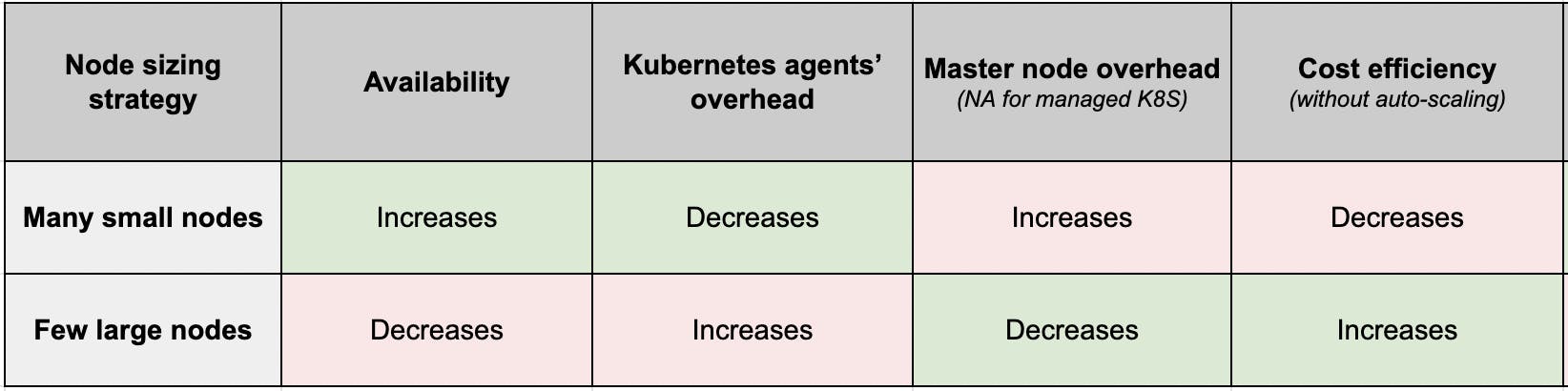
Master Node Overhead
💡 If you’re using a managed Kubernetes service, then the master nodes are managed by your service provider. So, in that case, you’ll not need to worry about master node overhead.
The following section is relevant for you only if you’re self-managing your Kubernetes cluster.
As the number of nodes increases, the Kubernetes Control Plane needs to manage more number of nodes. Such as running health checks on every node and ensuring communication between every node.
The smaller the nodes → The more nodes will be required to serve the desired capacity → The larger the overhead on the Kubernetes Control Plane (that runs on master nodes)
Your goal is to never choke the master node with this overhead. This is typically solved by:
Using more performant master nodes.
Ensuring that you’re well within the Kubernetes recommended limit of no more than 5000 nodes per cluster.
Let’s update the comparison table.

Cost Efficiency
Having many small nodes may lead to a fragment of underutilized resources on each of the nodes because the fragment may be too small to be assigned to any workload.
For example, let’s say, each of your pods requires 1.75 GB of memory.
Now, if you have 10 nodes with 2 GB memory each, then you can run 10 of these pods - and you’ll end up with 0.25 GB of unused memory on each node. That is a total of 12.5% of unused total memory.
Alternatively, if you have 1 node with 20 GB of memory, then you can run 11 pods. This leaves only 3.75% of unused memory.
The more the unused resources, the lesser the cost-efficiency.
Additionally, the daemon sets run by Kubernetes on every node (such as kube-proxy) consume a fixed amount of resources on the node irrespective of the size of that node. Meaning that the total amount of resources consumed by daemon sets for the same total cluster capacity is more with many smaller nodes as compared to a few larger nodes.
So, for the same total cluster capacity, more application instances can run if you choose larger nodes than smaller nodes. Making larger nodes more cost-efficient.
The updated comparison table looks like the below:
What you saw above was the case when cluster auto-scaling didn’t come into the picture. Let’s introduce that now.
When you have larger nodes, you also auto-scale your resources by a larger amount. This might lead to cases when you didn’t need that many more resources, and your resource remain unused. Not cost-effective.
So, what does one choose to optimize cost?
For applications that have similar resource requirements, or that run similar workloads (for example, only compute or only GPU), larger nodes are more cost-efficient.
If you want to deploy applications with different workloads, then we recommend that you create different node groups that cater to each workload to optimize resource utilization and cost.
Finally, this is how the comparison table looks like
Heterogeneous Nodes
The impact of using heterogeneous nodes will be a combination of what the table above outlines for many small nodes and a few larger nodes. In general, you’ll find it more complex to manage loads on heterogeneous node sizes compared to the other two sizing approaches.
Recommendations for Startups
So, should your startup use a few larger nodes or many smaller nodes, or heterogeneous nodes?
While the answer is governed by the type of applications that you want to run on these nodes, we’ll recommend the factors you should optimize for when you’re setting up the nodes for the first time (based on our experience of consulting other startups on the same):
- You moderately optimize for availability
- You do not worry about K8S agents’ or worker node overhead since they can easily be solved by choosing worker and master nodes of an optimal capacity.
- You optimize for costs during day-to-day operations more than that of autoscaling scenarios that are relatively less common for your scale.
- You do not worry about setting up node affinities for your applications unless there’s a specific use case, for example, to ensure that a Pod ends up on a node with an SSD attached to it, or to co-locate Pods from two different services that communicate a lot into the same availability zone
Using the above conclusions, we’ve seen that the following configurations work well for startups that have less than 10 microservices:
- Avoid using heterogeneous nodes.
- Have a minimum of 3 worker nodes (ie. 3-fold replication). As a startup, 3-5 worker nodes is sufficient.
- Across these 3 try to have as few nodes as possible that are maximal in size.
- Set up horizontal auto-scaling to spawn a maximum of 5 worker nodes.
- For the development environment, use nodes of one of the following sizes t3.medium, t3.large, m5.medium, or m5.large.
- For a production environment, it’s traffic-dependent. But, if you don’t know better right now, you can start with an m5 series (1x-4x large).
- If you can’t determine your desired cluster capacity, and you don’t know better:
- Assume the following capacity requirements for each instance of your application:
- 0.5-2 CPUs (0.5 CPU in dev environment, and 1-2 CPUs in production)
- 1-2 GB
- If you have a stateless application, turn on horizontal pod auto scaling (HPA)
- Monitor utilization, and iterate to determine a more exact desired cluster capacity for your application.
- Assume the following capacity requirements for each instance of your application:
Once your cluster running, regularly monitor CPU and memory across nodes so that you when it’s time to update the node sizes to suit the new needs.
What is your number one obstacle in managing resources for your Kubernetes cluster? Comment to let us know or join our Slack connect channel to schedule a 1:1 meeting with us where we share our recommendations for your specific requirements.
This article was written by Priyanshu Chhazed for Argonaut